图论:常用的最短路算法详解
引言
本文将讨论最常用的几个最短路算法,它们的用处各不相同,我们将探讨它们的原理,并给出伪代码实现。如果你通过这篇文章彻底理解了这些算法,那么将伪代码转换为可运行的源代码应该也不成问题:)
伪代码的规定:
- 出发点:s
- 目的地(如果只有一个目的地):d
Breath-first Search
Breath First Search(BFS),即广度优先搜索,刚学图论算法的朋友可能只用它进行图的遍历,但其实它也可以用来查找无权图的最短路径,只需加个parent数组记录前驱节点即可。
原理
广度优先搜索的原理十分简单,它从出发点一圈一圈地向外探索,直到遍历完所有点或遇到目的地。
实现
为了实现这一算法,我们只需重复以下步骤:
- 从探索的前沿
frontier中取出一个点cur,如果cur就是目的地,结束探索。 - 查看
cur的各个邻接点,若该邻接点尚未访问过,则将其加入frontier,并将其标记为访问过。(对于未访问过的节点i,parent[i]恰好为-1,因此我们可以不需要多余的visit数组判断访问过与否)
了解了实现的大致步骤,我们便可以写下如下伪代码:
parent[s] = s
parent[v] = -1 for all v != s
frontier = an empty queue
frontier.enqueue(s)
while !frontier.isEmpty() {
cur = frontier.dequeue()
for all neighbors next of cur {
if parent[next] == -1 {
parent[next] = cur
frontier.enqueue(next)
}
}
}Dijkstra’s Algorithm
BFS只能处理无权图,但在很多时候,各条路径所需的开销是不同的,当开销不为负时,我们就可以使用Dijkstra算法了。(为什么开销一定不能为负呢?下面原理有解释)
原理
Dijkstra是贪心算法(每次都想取目前的最优),从出发点开始,它每次从不在最短路径树上的点集合中寻找最近的点,将其加入最短路径树,并从该点松弛它的邻接边,直到遍历完所有点或遇到目的地。
松弛(relaxation)
本文讨论的对于有权图的最短路算法均用到了松弛。所以,到底什么是松弛?我们可以看一个简单的例子。
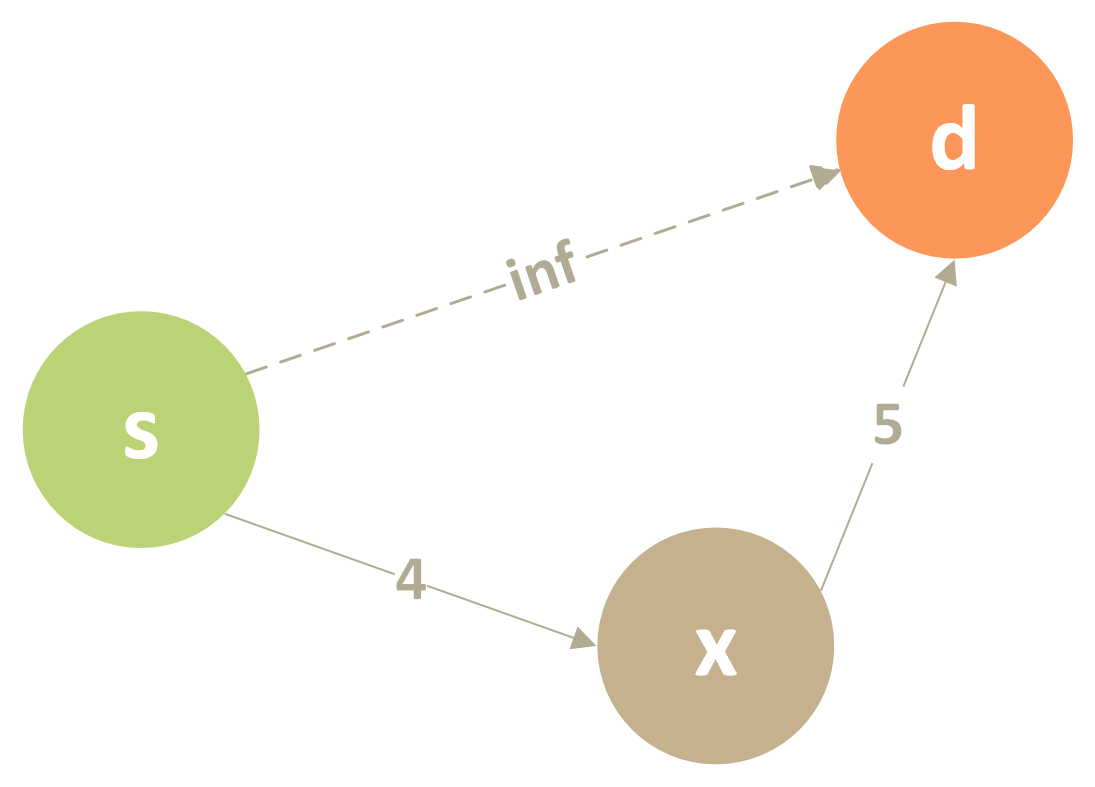
如图,当前从s到d的已知开销还是无穷大(即暂时不可达),但如果我们走经过x点的路径,4 + 5 = 9 < inf,因此我们就可以更新s到d的开销为9,这一过程就称为松弛。我们可以由这个例子写出如下典型的代码:
// dist[n]存储的是从出发点到点n已知的开销, l(x, y)是x点到y点边所带的权
if (dist[d] > dist[x] + l(x, d))
dist[d] = dist[x] + l(x, d);
// 也可以再简化下:
dist[d] = min(dist[d], dist[x] + l(x, d));为什么不能有负权边?
前面我们说到,若一个图要用Dijkstra算法,这个图必须没有负权边。这是由该算法的原理决定的,当我们从不在最短路径树上的点集合中找到一个最近的点时,我们会将其加入最短路径树,不再更改它的值。这样对没有负权值的图是合理的,但是若有负权值,这样最后的结果可能不是最短路径。我们可以考虑这样的情况:
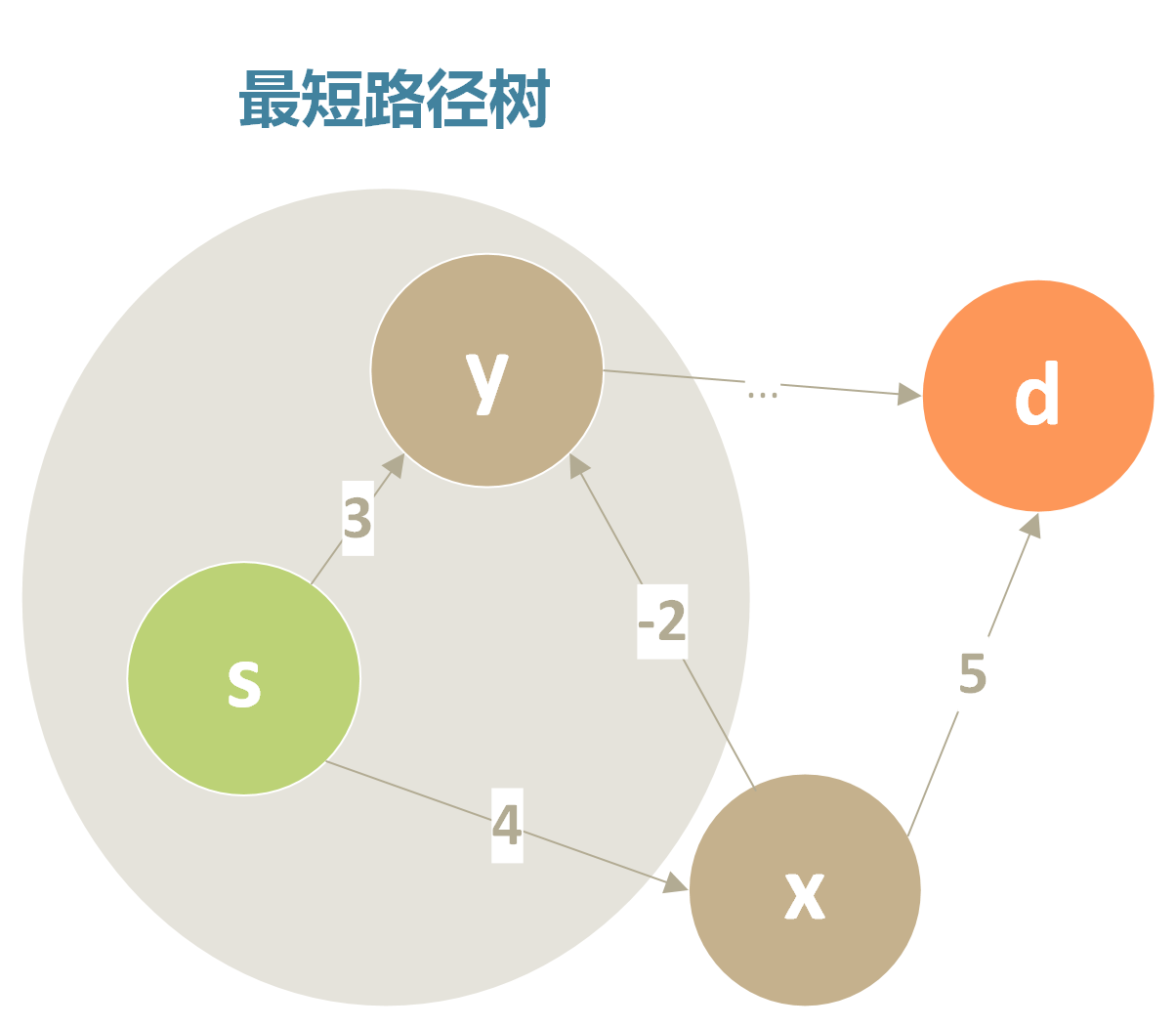
y点已经在最短路径树上了,开销为3,按照算法,我们不会再修改它的值,但由于x点到y点是负权值,4 - 2 = 2 < 3,实际的最短路径应该是s->x->y,距离为2,而不是3,这是Dijkstra算法无法处理的情况。
实现
其实Dijkstra和BFS是类似的,只不过因为边是有权值的,所以Dijkstra需要每次找到最近的点然后松弛它的邻接边。
这里我们使用优先队列这一数据结构来帮我们寻找不在最短路径树中最近的点,伪代码如下:
dist[s] = 0
dist[v] = INF, parent[v] = -1 for all v <> s
priority_queue.insert(s)
while (!priority_queue.isEmpty()) {
cur = priority_queue.deletemin()
for all neighbors next of cur {
if dist[next] > dist[cur] + l(cur, next) {
parent[next] = cur
dist[next] = dist[cur] + l(cur, next)
priority_queue.insert(next)
}
}
}A* Algorithm
BFS和Dijkstra算法是向四周一圈一圈地往外探索,当用于求解到其他多个点的最短路径时,这是合理的,但如果我们只是想求两个点之间的最短路径,这样就会做许多无用功,这时候我们就可以使用A*算法。
原理
A*算法较于Dijkstra算法就是多了一个启发函数(heuristic),它在计算时提供了一个目的地的导向,使我们能往那个方向探索。
启发函数
启发函数计算了当前解决问题的大概开销,在最短路径问题中,也就是当前点到目的地的距离。将到目的地的距离纳入考虑可以使我们更好地确定前往目的地的方向。
启发函数必须是可以简单快速计算出来的,否则会十分影响性能。关于启发函数,更多的内容可见:Heuristics。
实现
正如前面所说,A*算法与Dijkstra算法几乎一致,只是在优先队列排序中不仅仅考虑该点到出发点的距离,还要考虑到目的地的距离(启发函数)。因此我们可以很快地写出如下伪代码:
heuristic(cur, d):
return distance from cur to d
main:
dist[s] = 0
dist[v] = INF, parent[v] = -1 for all v <> s
priority_queue.insert(s)
while (!priority_queue.isEmpty()) {
cur = priority_queue.deletemin()
if (cur == d)
break;
for all neighbors next of cur {
new_cost = dist[cur] + l(cur, next)
if dist[next] > new_cost {
parent[next] = cur
dist[next] = new_cost
priority = new_cost + heuristic(next, d)
priority_queue.insert(next)
}
}
}Bellman-Ford Algorithm
Dijkstra算法和A*算法可以处理无负权值的最短路径问题,如果有负权值,我们就需要使用Bellman-Ford算法了,它还可以检测负权回路。
原理
对于一个顶点数为n的图,从一点到另一点的最短路径长度不会大于n-1,因此我们只要进行n-1次的遍历操作,对所有的边都尝试松弛,如果没有负权回路,我们就能得到出发点到其余各点的最短路径。
或许与Dijkstra算法对比更好理解:Dijkstra算法是从出发点开始向外扩张,依次处理邻接边,并且如果一个点加入了最短路径树,它就不会再修改这个点的值了;而Bellman-Ford算法每次都是从出发点重新开始依次进行”松弛”更新操作,可能修改各点的值,这样也就能应对负权边了(可以回看下这里)。所以其实Bellman-Ford算法就是比Dijkstra算法多做了一些松弛操作,正常情况是肯定可以得到最短路径的。
Bellman-Ford是动态规划算法,为了处理从出发点到其余各点的最短路这一大问题,先解决从出发点到一目的地最多用了k条边的最短路这一小的子问题。
定义:$f(d,k)$=从$s$点到$d$点最多用了$k$条边的最短路径长度
那么对于基准情况——不使用一条边:
根据松弛操作,我们可以写出以下递推式:
由此我们便可以递推得出到其余各点$v$的最短路径$f(d,n-1)$。
负权回路
负权回路并不是含有负权边的回路,而是权值之和为负的回路。
为什么有负权回路就不能求解正确的最短路径呢?可以看下面这个例子,我们只关注b点:
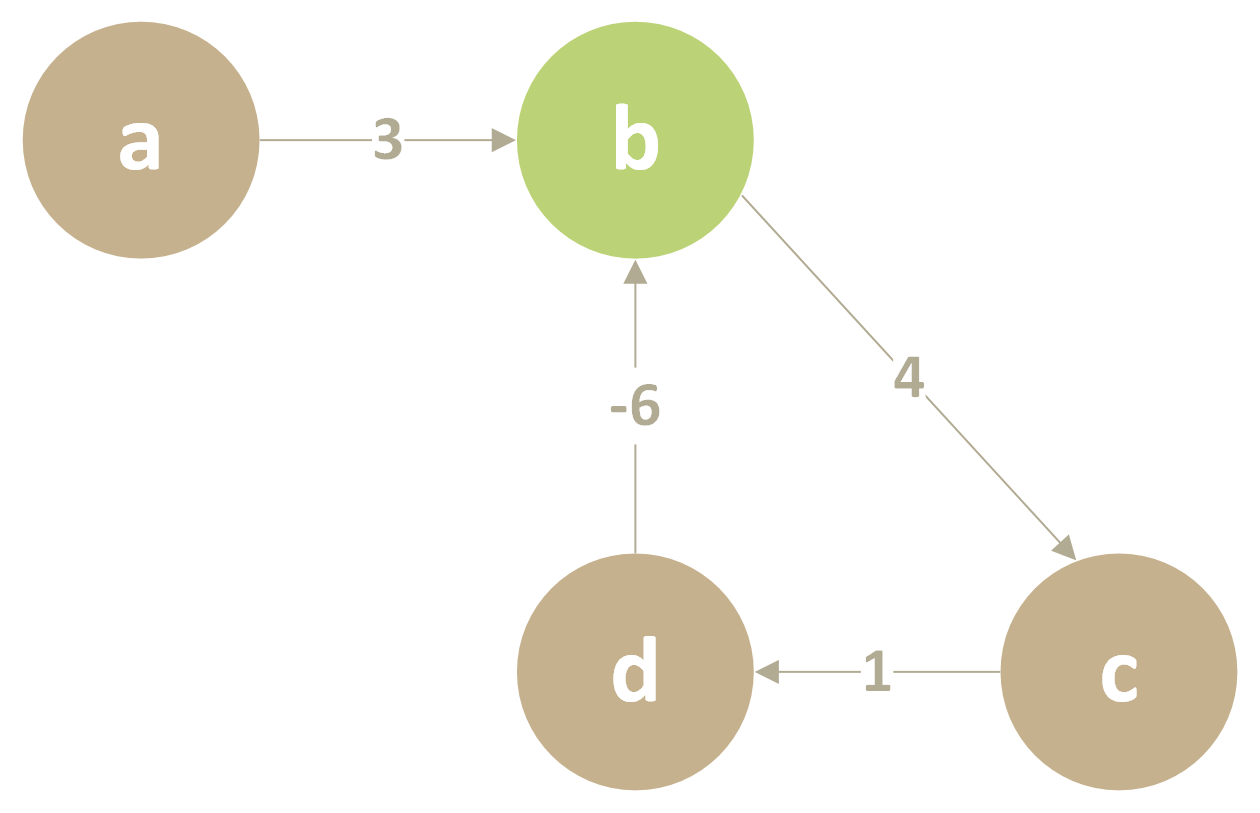
这个图中有4个顶点,因此我们需要遍历3次。在第一次的遍历中,到b的最短距离一开始是3,后面经过d点的松弛后变为了2,在以后的遍历中,每次遍历结束,到b的最短距离都减一,因此我们可以发现,如果存在负权回路,相关点的“最短路径”就可以一直减小下去(这也是我们检验是否存在负权回路的方法)。
实现
大致步骤:
- 遍历vertex_num - 1次,对所有边都尝试松弛操作
- 再遍历一次,如果某些点还能更新最短路径,则说明有负权回路,该图不存在最短路径
dist[s] = 0
dist[v] = INF for all v <> s
for (i = 1;i < n;i++) {
for all edge (v, w) {
dist[w] = min(dist[w], dist[v] + l(v, w))
}
}
for all edge (v, w) {
if dist[w] > dist[v] + l(v, w)
output "negative cycle found"
}Floyd-Warshall Algorithm
上述算法都是单源最短路算法,即从给定一点到另一点或其余各点,如果要求从任意一点到其余各点的最短路呢?当然,我们可以对每一个点调用上述算法,但Floyd-Warshall算法更为简洁优雅。
原理
和Bellman-Ford算法一样,Floyd-Warshall算法也是动态规划算法,只不过前者是与边相关,而后者与点相关。因此如果你理解了上一算法的动态规划思想,那么这一算法你也就能很快的理解了,我们在这里就不过多解释了。
定义:$f(i,j,k)$ = 从点$i$到点$j$中途最多经过了$1,…,k$这些点的最短路径长度
基准情况——不经过任何点:
由松弛操作,我们可以得出以下递推式:
由此我们便可以递推出从任意点$i$到任意点$j$的最短路径$f(i,j,k)$。
实现
算法的核心代码其实就五行,十分简洁,思想就是对任意两点尝试经过各个点松弛。
for (k = 1;k <= n;k++) {
for (i = 1;i <= n;i++) {
for (j = 1;j <= n;j++)
dist[i,j] = min(dist[i, j], dist[i, k] + dist[k, j])
}
}算法总结
| 算法 | 用处 |
|---|---|
| BFS | 无权图,1->all |
| Dijkstra’s Algorithm | 有权图,无负权边,1->all |
| A* Algorithm | 有权图,无负权边,1->1 |
| Bellman-Ford Algorithm | 有权图,无负权回路,1->all |
| Floyd-Warshall Algorithm | 有权图,all->all |
参考
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!